
バートリーのさいとうです。
今回は
【Rails】カラムの値を配列の形で取得したい場合に使えるpluckメソッドを徹底解説
していきます。
railsで任意のカラム(列)の値を複数取得して、配列で返したい時、ありませんか?
答えからお伝えします。
例えば、以下のようにDBに保存されているusersテーブルのnameカラムの値だけを取得したいとします。
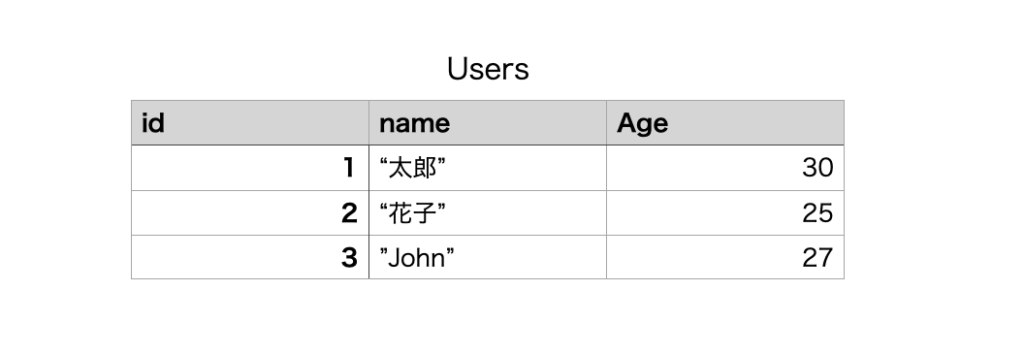
この時に、使えるのがpluckメソッドです。
具体的には、このように記述します。
user_names = User.pluck(:name)
p user_names
#=> ["太郎", "花子", "John"]これで、カラムの値を配列で取得することができました。
結論はお伝えしたので、ここからはpluckメソッドについて深掘りをしていきます。
具体的には
- plcukメソッドによって呼び出されるSQL
- pluckメソッドとselectメソッドの違い、お互いの使い分けのポイント
- pluckメソッドを利用する時の注意点
を実例付きで解説していきます。
読み進めれば、pluckメソッドについての理解がグッと深まると同時に、メソッドによって返される「型」について理解することができます。
型について理解できると、エラーが出る原因もわかるようになるかと思いますので、ぜひ最後までご覧ください。
plcukメソッドによって呼び出されるSQL
先ほどのコードをもう一度確認しましょう。
user_names = User.pluck(:name)このpluckメソッドによって呼び出されるSQLは以下の通りです。
SELECT `users`.`name` FROM `users`selectの後ろにusers.nameという風に記述されていますね。
これは、「usersテーブルのnameカラムをとってきてくださいね〜」ってことを示しています。
pluckメソッドとselectメソッドの違い、お互いの使い分けのポイント
pluckメソッド最強じゃん!って思ったら、同じように任意のカラムの値を取得する方法がありました。
selectメソッドです。
使い方を見ていきましょう。
User.select(:name)生成されるSQL文は
SELECT `users`.`name` FROM `users`見ていただいたように、使い方はpluckメソッドとほぼ変わりません。
生成されるSQL文に関しては、全く同じです。(=つまり取得できる値は全く同じということになります。)
では、何が違うのでしょうか?
ここで理解しなければいけないのが、返り値の「型」です。
返り値の型が異なるpluckとselect
先ほどのpluckメソッドは、配列という型で返ってきました。
user_names = User.pluck(:name)
p user_names
#=> ["太郎", "花子", "John"]一方で、selectの返り値の型は以下のようになります。
user_names = User.select(:name)
p user_names
#=><ActiveRecord::Relation [
#<User id: nil, name: "太郎", age: nil>,
#<User id: nil, name: "花子", age: nil>,
#<User id: nil, name: "John", age: nil>
#], >selectも確かに配列で返ってきていますが、その前にActiveRecord::Relationと書いてあります。
実は、selectは配列ではなく、ActiveRecord::Relation型で返ってきています。
ActiveRecord::Relation型の返り値を持つメソッドには、whereやall, joinsなどがあります。
では、この型が違うことで、どんな変化が生まれるんでしょうか?
自分が使い分けの判定基準にしている点として、3つあります。具体的には
- ActiveRecord::Relationで返るとDBの値を更新できる
- 配列で返ると、DBのデータ更新はできないが、効率的にデータを取得し表示することができる。
- 配列とActiveRecord::Relationで利用できるメソッドと、メソッドチェーンの利用可否が決まる
です。
順番に説明していきます。
1. ActiveRecord::Relationで返るとDBの値を更新できる
先ほど見ていただいたように、
<User id: nil, name: "太郎", age: nil>, という、DBのレコードが返ってきていることがわかります。つまり、返り値を編集・更新できます。
一方で、pluckは、DBのレコードではなく、レコードから取得した値だけを配列にしてしまうので、DBを直接更新することができません。
イメージとしては、wordのファイルを取得すれば編集・更新できるけど、それをpdf化したら(一般的には)できなくなる仕組みに近いものがありますね。
2. 配列で返ると、DBのデータ更新はできないが、効率的にデータを取得し表示することができる
逆に、pluckメソッドはレコードという重たいオブジェクトを取得しない分、効率的にピンポイントでデータを取得することができます。
なので、特定のカラムの値を配列で取得したい!と思った時に真っ先に利用を考えて良いと思います。
正し、データの量によっては、mapメソッドの方が効率的な場合があります。詳しくは、以下の記事を参照ください。(詳しくは後述します)

3. 配列とActiveRecord::Relationで利用できるメソッドと、メソッドチェーンの利用可否が決まる
railsガイドによると
文中でメソッドチェインができるのは、その前のメソッドが
ActiveRecord::Relation(all、where、joinsなど) をひとつ返す場合です。
とあります。
メソッドチェーンとは
user_names = User.select(:name).where(name: "太郎")のように、メソッドを連結させる記述方法です。
これが、ActiveRecord::Relationを返すメソッドなら可能ですが、pluckは配列を返すので、出来ないということです。
でも大丈夫、pluckを利用する時でも同様に条件指定が可能です。↓
user_names = User.where(name: "太郎").pluck(:name)という風に、pluckを最後に持ってくることで条件を指定したり、distinctメソッドで重複を弾けたりします。
ポイントは、pluckメソッドの後ろにはメソッドを繋げないことです。
思ったこと
このように、メソッドの返り値(何をするか)によって、結構変化があります。
それこそ、先ほど説明した返り値の型がわかってなくて、undefined methodあーだらこーだらと困った経験、みなさんにもありませんか?
この型がわかるだけで、7, 8割は解決できるはずです。
pluckメソッドを利用する時の注意点
先ほどの触れましたが、pluckメソッドは、特定のカラムを取得する時にめちゃ便利なメソッドです。
しかし一方で、すでにインスタンス化されたオブジェクトには、pluckを使うのは非効率です。
インスタンス化されたオブジェクトとは、以下のusersのようにすでにDB取得されたオブジェクトのことです。
users = User.all #←このusers
user_names = users.pluck(:name)ここでは、User.allでSQL文を生み出しusersテーブル全てのレコードを取得した後に、nameカラムの値を取得するために再度SQL文を出力することになっています。
これでは、SQL文を余計に出力することになってしまいます。そこで、mapメソッドを代わりに利用します。
users = User.all
user_names = users.map(&:id)こうすることで、SQL文を再度発行することがなくなり、アプリの処理速度改善につながります。
(補足)
ベンチマークあたりのことは詳しくわからないのですが、基本的にはmapを使うべきという意見が多いように感じました。

の中の

こちらのコメントなどで見られるように、状況によってはpluckが早い場合があるようです。
以上が、pluckの深掘りでした。お疲れ様でした!
まとめ
いかがだったでしょうか。
今回説明したような返り値の型とか、生み出されるSQL文のこととか、僕にはまだまだ勉強しなきゃいけないことがたくさんあると、再確認になりました。
このブログは、月に15本を目標に、実務から学んだプログラミングのあれこれを発信しています。
誰かのためになれば、嬉しいです。
最後まで読んでいただき、ありがとうございました。
それでは。
【参考記事】









